企画制作の裏話や、本には書ききれなかった補足事項など、本書をより楽しんでいただくための文章を著者に寄稿していただく企画です。
『京都の災害をめぐる』には、各地点の写真のほか、史料の画像を載せるようにしました。でも、特に近世以前のものに関しては、筆の続け字で書かれていて「何て書いてあるのか読めない」という反応もいただきそうです。
一般にくずし字と呼ばれるこのような文字(あるいは、書き方のスタイル)、読んでみたいという方はたくさんおられるようで、その読み方についての書籍や講座もたくさんあります。私の場合は、歴史地震の研究のために必要だったこともあり、数年前から仲間とともに勉強を続けています。仕事のためとも言いながら、文字を読むこと自体のおもしろさにもハマってしまっているというのが正直なところです。
研究者はもちろん、歴史や古典に興味のある方々はくずし字の読みかたを習ったりご自分で勉強したりして、いろいろな本を読んでおられることと思います。私や大邑さんも関わっているプロジェクト「みんなで翻刻」(https://honkoku.org/)では、市民の方にもご参加いただいてオンラインで史資料を読み進めています。これらは人が読むということを前提としていますが、最近では人工知能(AI)によってくずし字を読む(現状では文字を認識する)ことが行なわれるようになってきました。
さて、2019年11月11日に「日本文化とAIシンポジウム2019AIがくずし字を読む時代がやってきた」というシンポジウムがあり参加してきました。225名の参加があったとのことでこのテーマへの関心の高さがうかがえます。このシンポジウムについての詳細はWebサイト(http://codh.rois.ac.jp/symposium/japanese-culture-ai-2019/)をご参照ください。当日のインターネット中継の録画もみることができます。
シンポジウムでは既に公開されていた「日本古典籍くずし字データセット」にデータが追加され、100万文字を越えたことが発表され、また「KuroNetくずし字認識サービス」も公開されました(http://codh.rois.ac.jp/news/#20191111)。
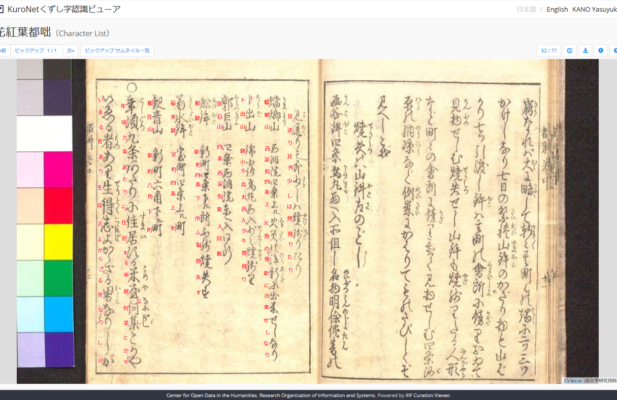
「KuroNetくずし字認識サービス」を使うと、インターネット上で公開されているデジタルアーカイブの画像でAIによるくずし字認識を試すことができます(ただし、IIIFという規格に準拠している必要があります)。『京都の災害をめぐる』の81番「霰天神山」では『花紅葉都咄』に書かれた天明京都大火での山鉾の被害状況を紹介しています(別の余話でもご紹介しました)。この引用したページで試してみた結果が冒頭の画像です。なお、『京都の災害をめぐる』では、京都府立京都学・歴彩館の京の記憶アーカイブの『花紅葉都咄』の画像を掲載していますが、ここでは国文学研究資料館の新日本古典籍総合データベース(http://kotenseki.nijl.ac.jp/biblio/200021949/viewer/1)の画像を用いました。
地震研究においてくずし字を読むということはAIとの協力関係については、日本地震学会の広報紙『なゐふる』(https://www.zisin.jp/publications/naifuru.html)の119号(2019年10月発行)に『地震史料を「読む」』という記事を書いています。ご興味をお持ちの方は参照しただければと思います。
最後に、簡単にやり方を書いておきます。自分でもやってみたいという方の参考になれば幸いです。
(1) 「KuroNetくずし字認識サービス」(https://mp.ex.nii.ac.jp/kuronet/)のページでログインします。
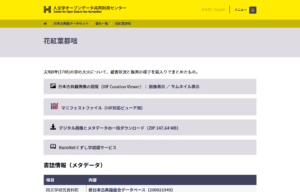
(2) 書誌情報のなかにあるIIIFのアイコンを、別のウィンドウに開いておいた「KuroNetくずし字認識ビューア」の表示部にドラッグ&ドロップします。
(3) 右上の「■」のボタンをクリックすると領域を指定できる状態になるので、認識したい領域を囲みます。
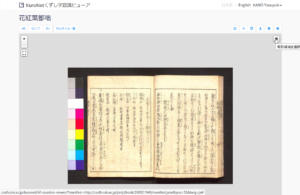
(4) 囲った薄い青色の部分をクリックすると「KuroNetくずし字認識サービス」のリンクが出るのでクリックします。
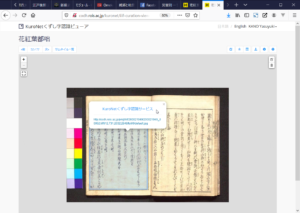
(5) 画面が「ダッシュボード」に移動します。「OCR予約」をクリックしてしばらく待ちます。
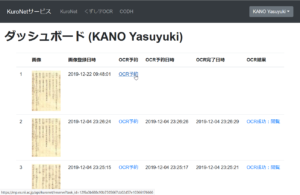
(6) 認識に成功すると結果が画面に表示されます。
謝辞:情報・システム研究機構 データサイエンス共同利用基盤施設人文学オープンデータ共同利用センターのKuroNetくずし字認識サービスと、国文学研究資料館の新日本古典籍総合データベースを利用しました。